A New Era In The Black Kite Compliance Module: Black Kite Research Pushes Boundaries For Text-Based Cyber-Aware AI
Black Kite Research is proud to launch UniQuE Parser 2.0: our document parser and natural language processing model now reoriented and tuned for the cybersecurity domain.
UniQuE is the AI engine driving Black Kite’s compliance module, which correlates compliance documentation to 14 regulations and standards: NIST 800-53, NIST CSF, ISO 27001, GDPR, CCPA, CIS CSC-20, COBIT 5, PCI-DSS, HIPAA, NIST 800-171, CMMC, NY DFS, SA-2021, and OTA 2017. It is an automated compliance solution on its own.
In this release documentation, we will start at the core of the design, and the motivation behind cybersecurity compliance automation, answering questions like:
Why do we need automation in the first place?
Following this will be a deep dive into the technology behind text-based AI and NLP (Natural Language Processing), answering the questions of:
What is text-based AI?
Why is NLP (text-based AI) becoming essential for the cybersecurity industry?
Why do we need a context-aware or cyber-aware AI for the text - which is the main motivation behind UniQuE Parser 2.0?
As we reveal the technology and methodology, including the data and models visualizing the advancements, we ensure careful attention is paid toward the challenges and barriers in implementing a text-based AI project.
Throughout this project, we have benchmarked alongside other text-based AI models and publicly available language models, including an already-tuned model. The team additionally studied the metrics necessary to turn this research into a functional product advancement.
Now let’s get into how this feature will be utilized within the Black Kite platform.
Introduction
Think of a person who can read, understand, and speak English. An individual randomly picked out of a crowd, who reads information sources such as Wikipedia, and knows/understands basic concepts.
If you said to him: “Abraham Lincoln is a Hollywood actor living in Los Angeles,” he can say, “You are wrong!” He has a certain level of intelligence or relative knowledge.

His cybersecurity knowledge is average, as is the case for many other domains. When you talk about “physical security”and “cloud access control,” he can say, “You are talking about security, right? Those two mean the same”. Are they the same? Let’s find out.
Our Motivation
In general, compliance means abiding by a set of rules. Compliance in corporate and organizational management refers to ensuring that your business and its personnel comply with all applicable laws, rules, regulations, standards and ethical guidelines. It also entails abiding by local, state, and federal laws and corporate policies.
Regarding Information and Cyber Security Compliance, there are different standards and best practices depending on the company’s geography, sector, and business environment. If you take a step back and look at the whole picture of supply chain security management, this level of automation saves the company a considerable amount of human resources.
Now consider the perspective of a vendor. Each company (vendor) is in a business deal that requires a different standard. For each business, the vendor has to fill in a separate questionnaire shaped around a different standard, framework or regulation.
Automation is key in supply chain cybersecurity
Two years ago, Black Kite recognized this need and introduced the original UniQuE Parser 1.0, allowing vendors to upload their compliance documentation to the parser. The current parser processes each paragraph or item in the compliance document or custom questionnaire and correlates it to the existing standards.
Relation to Biden’s Executive Order
In May 2021, months after Solarwinds and days after the Colonial Pipeline attack, the White House released Executive Order (EO) 14028, titled “Improving the Nation’s Cybersecurity.” The order aimed to enhance cybersecurity across all federal agencies, as well as any third parties seeking to conduct business with them.
When we breakdown the order, it essentially boils down to:
- federal cybersecurity modernization,
- removing obstacles to information sharing on threats
- enhancing supply chain security for software
- bringing the Federal Government's incident response protocol into compliance
- enhancing the detection of cyber security flaws
- increasing the federal government's capacity for investigation and recovery
Each sector that does business with the government, plus the government itself, has its own take on the executive order. One thing in common with each different aspect: the need for automation.
Without automation, no action item would be sustainable in the long run.
The need for automation is explicitly highlighted in “Sec. 3. Modernizing Federal Government Cybersecurity.” order reading: “(iii) incorporating automation throughout the lifecycle of FedRAMP, including assessment, authorization, continuous monitoring, and compliance;”
Note that automation, continuous monitoring, and compliance are all expressed in the same sentence. Other items that hint at the automation need in the compliance process are:
(iv) digitizing and streamlining documentation that vendors are required to complete, including through online accessibility and pre-populated forms;”
(v) identifying relevant compliance frameworks, mapping those frameworks onto requirements in the FedRAMP authorization process, and allowing those frameworks to be used as a substitute for the applicable portion of the authorization process, as appropriate.
Introducing UniQuE Parser 2.0: A Smarter Parser with a Fine-Tuned NLP Algorithm
UniQuE Parser 1.0 was built using a parsing ad and off-the-shelf AI mechanism, namely TensorFlow (TF) 2.0, to identify similarities between standards, compliance artifacts and custom questionnaires. Black Kite Research and Engineers, inspired by Universal Sentence Encoder, implemented the system.
UniQuE Parser 1.0 achieved something that had never been done before in cybersecurity: enabling ad-hoc parsing and mapping of cybersecurity documents to industry standards.
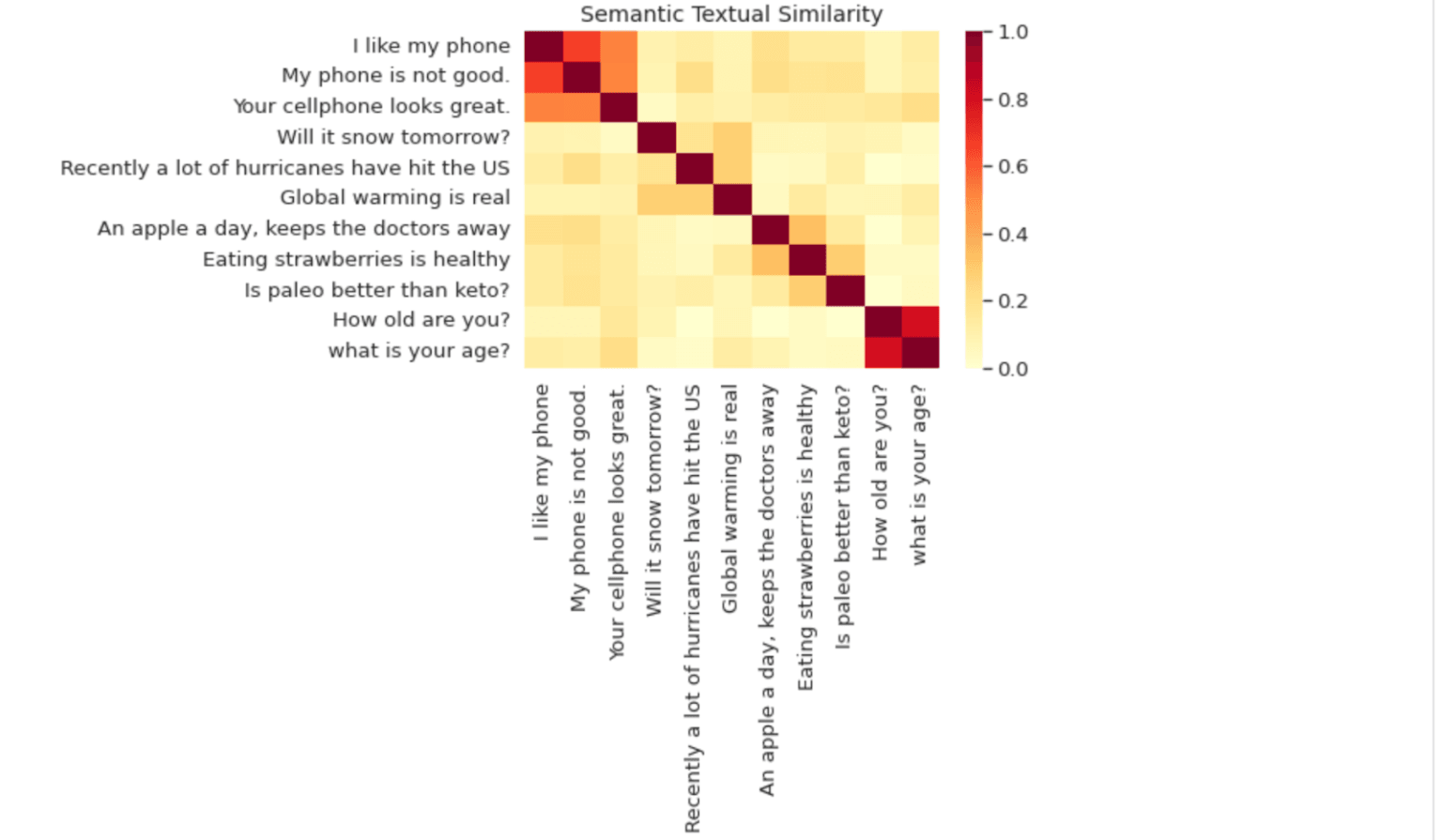
An example output of a Universal Sentence Encoder for general sentences (source)
Nevertheless, Universal Sentence Encoder (USE) and other over-the-shelf text-based AI models, have advantages that are offset by decreased context awareness. The main challenges in domain-specific AI are:
- There’s not a one-algorithm-fits-all approach in text-based AI models
- Current text-based models - in the most naive sense - identify text similarities to a certain level. Recall our “English-speaking, intelligent person” analogy. Generic language models fail to capture domain jargon and domain-specific terms. That’s because these pre-trained models are designed for general English vocabulary and are based on Wikipedia and Google search results.
- In UNIQUE Parser 1.0, these challenges were overcome through manual tuning beforehand and adding context-awareness in a different fashion.
- Training a model from scratch requires good quality and high-volume data. When this is a language model, the order would be on the level of millions.
- A domain-specific AI, most of the time, requires annotated data. This data has to be labeled by subject matter experts.
- Apart from labeling, data creation itself is another challenge.
- Human judgment is expensive and the human mind is fuzzy.
An AI with a Cybersecurity Certification
When Bob Maley, CSO of Black Kite, reviewed this project's results, he said, “We gave our parser a cybersecurity certificate,” which is true in a sense. For example, this AI knows the difference between “access control” for digital systems and “access control” for physical security. Undoubtedly, s/he will achieve more complex tasks in cyber security in the future.
What is fine-tuning in this context?
In fine-tuning, an approach of transfer learning, a model is trained with a dataset using the Apriori algorithm. Then, the same model can be trained with another data set, which might be a domain-specific dataset. The second dataset is much smaller than the original one, by 10%.
What is apriori?
According to educative.io, “The Apriori algorithm is used for mining frequent itemsets and devising association rules from a transactional database. The parameters “support” and “confidence” are used. Support refers to items’ frequency of occurrence; confidence is a conditional probability.
Items in a transaction form an item set. The algorithm begins by identifying frequent, individual items (items with a frequency greater than or equal to the given support) in the database and continues to extend them to larger, frequent itemsets.”
Typically, we change the learning rate to a smaller one so it does not significantly impact the already adjusted weights of the underlying language. You can also have a base model working for a similar task and then freeze some of the layers to keep the old knowledge when performing new training sessions with the latest data. The output layer can also be different and have some of it frozen regarding the training.
Let’s get technical
The Methodology
Fine-tuning requires a moderate amount of train and test data. The amount of data needed for this task is much less than training a model from scratch, but, again, data annotation is perhaps the most crucial part of a Natural Language Processing (NLP) task. A more user-friendly term for this process is called “Human Judgment''.
Our human judges labeled cybersecurity texts in several ordinal scales. We made this process human-friendly by creating text labels. These labels, then, have been converted to numeric values and fed into the model.
Benchmarking with other models
To measure the model's accuracy, we benchmarked it with similar pre-trained models available on the model library HuggingFace.
Subject matter experts in cybersecurity and information security (who were not involved in developing the model) labeled the test data. Our cyber-aware AI model competed with two other models:
- SciBERT (Scientific BERT): SciBERT is a pre-trained BERT-based language model for performing scientific tasks in the field of Natural Language Processing (NLP). Although we knew it achieved much better scores in Biomedicine than Information Technology, we have still been given a chance and used it for benchmarking.
- USE (Universal Sentence Encoder): This is the baseline model not fine-tuned with any specific domain.
Measuring a Score For Binary Classification
Context: Binary classification is classifying a sample (sentences/passages in the context of the compliance module) into one of the two categories:
[An “Event” or 1 or a “Positive Sample”] vs. [a “Non-event” or 0 or a “Negative Sample”]
In the context of the compliance module an “Event” is defined as: This sentence includes the information we are looking for.
And a “Non-Event” is defined as: This sentence does NOT include the information we are looking for.
Scoring: The statistical models that we use assign each sample a numeric indicator out of 100% (e.g., 65%) indicating how likely the model thinks this particular case is an event or not (a non-event). Using this so-called “score,” we effectively get a sorting of the samples we have in hand.
After sorting with reference to the score, the table can look like this, for example,
ID | Sample Sentence | Score |
|---|---|---|
1 | Some sentence, or passage | 95% |
2 | Some sentence, or passage | 88% |
3 | Some sentence, or passage | 83% |
4 | Some sentence, or passage | 70% |
5 | Some sentence, or passage | 55% |
6 | Some sentence, or passage | 40% |
To get a class out of the score, we use a threshold (or sometimes called a ‘cutoff’ ). Say we choose 70% as our threshold and predict/classify all samples with a score of more than 70% as 1 (Event) and the rest as 0 (Non-event).
ID | Sample Sentence | Score | Predicted Class |
|---|---|---|---|
1 | Some sentence, or passage | 95% | 1 |
2 | Some sentence, or passage | 88% | 1 |
3 | Some sentence, or passage | 83% | 1 |
4 | Some sentence, or passage | 75% | 1 |
5 | Some sentence, or passage | 55% | 0 |
6 | Some sentence, or passage | 40% | 0 |
Motivation: Ideally (more like unrealistically), we want to be able to classify (via a prediction) each sample that is (or later turns out to be) an Event as an Event, and each sample that is a Non-Event as a Non-Event.
i.e., We want a classification that predicts 1 for every 1 and 0 for every 0 in this table.
Challenge: Not surprisingly, the ideal case is far from realistic. Usually, the real classes of these samples turn out to be different from the predicted class for many samples.
Example of Prediction with threshold = 70%
ID | Sample Sentence | Score | Predicted Class | Real Class |
|---|---|---|---|---|
1 | Some sentence, or passage | 95% | 1 | 1 |
2 | Some sentence, or passage | 88% | 1 | 1 |
3 | Some sentence, or passage | 83% | 1 | 0 |
4 | Some sentence, or passage | 75% | 1 | 1 |
5 | Some sentence, or passage | 55% | 0 | 1 |
6 | Some sentence, or passage | 40% | 0 | 0 |
We can see in the table that:
- The sentence with ID=3 is classified as 1, where it actually is 0. This is a false positive.
- And conversely, the sentence with ID=5 is classified as 0, where it actually is 1. This is a false negative.
Classification Metrics (the ones we care about in this application):
TPR (True Positive Rate) = What portion of the real events (1s) we predicted right (we predicted a 1)
For the table above, this is:
[# of times we predicted as 1 and we were right] / [Total # of times it was a 1]
= 3 / 4
= 75%
Intuitively TPR is:
FPR (False Positive Rate) = What portion of the real non-events (0s) we predicted wrong (we predicted a 1)
[# of times we predicted as 1 and we were WRONG] / [Total # of times it was as 0]
= 1 / 2
= 50%
In the ideal case there is a threshold where all real 1s stay above the threshold score and all real 0s stay below the threshold → perfect classification with 100% TPR and 0% FPR.
But as we mentioned, this is not realistic. Instead, we compromise between getting a better (higher) TPR and a better (lower) FPR.
The Trade-Off: The higher the threshold is, the more precautious we are when deciding/predicting that something is an event → we get a lower FPR but also a lower TPR.
The lower the threshold is, the less precautious we are when deciding/predicting that something is an event → we get a higher TPR but also a higher FPR.
In the extreme case where the threshold is 100% (this is not a real case, only mentioned to give a better understanding of the tradeoff), we predict everything to be a 0. Since there is no positive prediction, we can not have a false positive, and FPR = 0%. But, at the same time, we also get a 0% TPR.
The other extreme case is where the threshold is 0%, and we predict every sample to a 1. We get 100% TPR (all of the real 1s are predicted to be 1) and 100% FPR (we predicted every real 0 as a 1).
The Predictive Power of a Score: The power of scoring gives us room to choose thresholds and gauge higher TPRs, without paying too high of a price (lower FPRs, or not too high FPRs).
Every score behaves differently over the 0 - 100% threshold range. Some are good at having a not so high FPR with a great TPR, some are good at having almost no false positives (FPR ~ 0) with a decent (but not very high) TPR.
Since the tradeoff between these metrics becomes hard to grasp algebraically, the ROC (Receiver Operating Characteristic) curve comes to aid us with a great visualization of it.
ROC Curve
The ROC curve reveals how a score behaves for different thresholds in a single view.
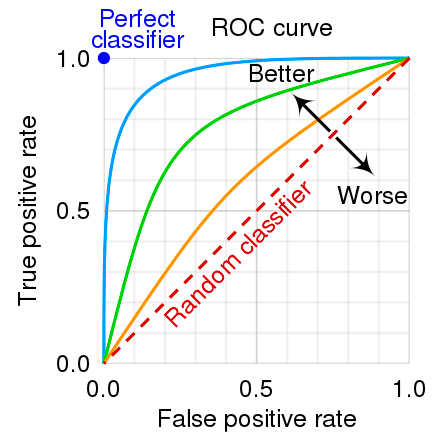
The curve is created with these four steps:
- Start at a 0% threshold and get a pair of (TPR, FPR) as mentioned above. At the 0% threshold the first pair will always be (0%, 0%) for any score.
- Increase the threshold gradually and collect a series of (TPR, FPR) pairs.
- Continue until the other extreme where the threshold is 100%.
- Plot the line connecting the pairs.
Reading the ROC Curve
- The higher (leaned towards top left corner) the curve, the better the classifier is.
- If the curve is higher around the lower left corner, the classifier is good at having decent TPR with low FPR.
- If the curve is instead higher around the upper right corner, the classifier is good at having great TPR with a not too high FPR.
The diagonal line represents the performance of a naive model (randomly predicting for all samples of 1s or 0s). This line is the “Bare Minimum”, because we get this predictive power for free.
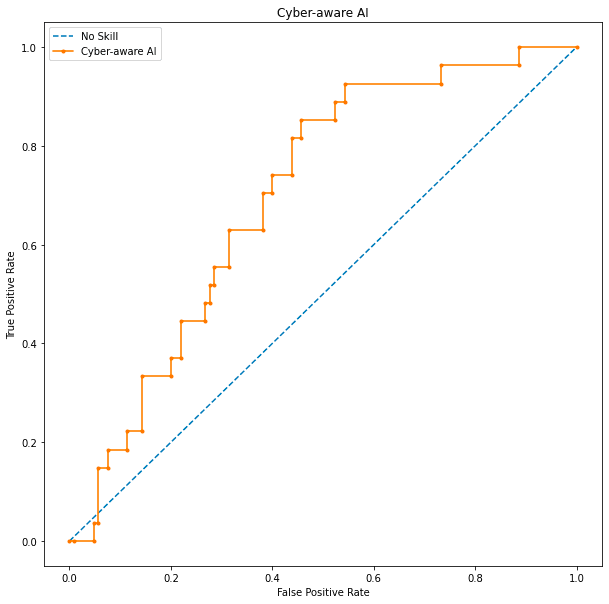
ROC curve for Cyber-aware AI
What is the Gini Coefficient?
In a nutshell, the Gini coefficient in machine learning tells us how close our model is to being a “perfect model” and how far it is from being a “random model.” Thus, a “perfect model” would get a Gini score of 1, and a “random model” would get a Gini coefficient of 0.
It is calculated to be 2 X (AUC - ½ ), which is very similar to the AUC but compares the model to the naive one by subtracting the ½ attributed to the naive model and scaled to have 0 min and 1 max by multiplying with 2. Intuitively it is the same metric as AUC, but with a naive benchmark, and comparison integrated.
We normalized the results to the USE model by putting the USE model’s Gini coefficient as a baseline of 1. Our Cyber-Aware model achieves a 25% better Gini score, while SciBERT achieves 2% worse score.
Model | Normalized Gini Coefficient |
|---|---|
SciBERT | 0.98 |
Cyber-Aware | 1.25 |
USE | 1 |
Correlation Coefficient
Correlation is a common term in statistics. In the most naive sense, correlation means any kind of relationship between two variables. As a performance metric, we compare the manual data label with the predicted labels of the models. It tells us essentially whether predicted labels move in the same direction as human labels.
The correlation coefficient shows the strength of a relationship between two variables. The correlation coefficient's values range between -1.0 and 1.0. If the correlation is close to 1.0 or -1.0, then there is a strong correlation while there is no correlation at 0. Taking USE’s correlation coefficient as 0.5, our Cyber-aware AI achieves a 0.59 correlation, while SciBERT achieves a 0.35 correlation.
Model | Normalized Gini Coefficient |
|---|---|
Cyber-Aware | 0.59 |
USE | 0.5 |
SciBERT | 0.35 |
True Positive Rate (Recall) vs. Extreme False Positive Rate
For the same threshold, whether this is an alarm or not, the FPR and TPRs are listed below.
Model | Normalized TPR | E_FPR |
|---|---|---|
Cyber-Aware | 11.5 | 7% |
USE | 1 | 0% |
SciBERT | 25 | 75% |
F1-Score
F1-Score is a measure combining both precision and recall. It is generally described as the harmonic mean of the two. The idea is to provide a single metric that weights the two ratios (precision and recall) in a balanced way, requiring both to have a higher value for the F1-score value to rise.
Note that Cyber-Aware AI has the highest F1 score, meaning it achieves the best performance when it comes to optimization of TPR and FPR
Model | Normalized TPR |
|---|---|
Cyber-Aware | 6.8 |
USE | 1 |
SciBERT | 5.8 |